
dbtのモデルでローカルからBigQueryにビューを作成してみる
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
7月から所属事業部がデータアナリティクス事業本部からデータ事業部に改名されました。
データエンジニアのはんざわです。
前回のブログでは、dbt CoreでローカルからBigQueryを操作するためのセットアップ方法を紹介しました。
その際にデフォルトで登録されているサンプルクエリを実行してみましたが、今回は自分でクエリの作成と登録を行ってみたいと思います。
前提
- ローカルのセットアップ内容は前回のブログと同じ
- ビューを構成するテーブルには、BigQueryの一般公開データセットを使用する
- テーブルの参照にsourceを使用する
検証のゴール
今回の検証では、BigQueryの一般公開データセットのgithub_nestedとshakespeareを使用し、それぞれのテーブルからデータ件数を取得するビューをdbtで作成したいと思います。
環境の準備
まずは環境を準備したいと思います。
dbtの環境は、前回の検証で作成したものを再利用します。
dbtのバージョンは以下の通りです。
Core:
- installed: 1.8.3
- latest: 1.8.3 - Up to date!
Plugins:
- bigquery: 1.8.2 - Up to date!
また、dbtのプロジェクトはtest_projectで~/.dbt/profiles.ymlの中身は以下の通りです。
test_project:
outputs:
dev:
dataset: dbt_dataset
job_execution_timeout_seconds: 300
job_retries: 1
location: US
method: oauth
priority: interactive
project: [プロジェクトID]
threads: 1
type: bigquery
target: dev
クエリを作成
クエリを準備するにあたって、参照元となるローデータとデータの変換や集計を行うSQLクエリの2つを定義する必要があります。
dbtにおいて、参照元となるデータを ソース(source) と呼び、データの変換や集計を行うSQLクエリを モデル と呼びます。
これらのファイルをデフォルトでは、modelsディレクトリ配下に格納します。
また、modelsディレクトリ内のサブディレクトリに入れ子にすることも可能です。
デフォルトで作成されたexampleを削除し、新たにdbt_testと名付けたサブディレクトリを作成します。
この時点でのmodelsディレクトリ配下は次の通りです。
models
└── dbt_test
ソース(source)を作成
次にsourceを作成します。
ビューを構成する元となるgithub_nestedとshakespeareをsourceで定義します。
sourceとは、参照元となるローデータを指します。
任意の名前の.ymlファイルをmodelsディレクトリに配置することで、SQLクエリから呼び出すことができます。
今回の検証ではsrc_tables.ymlと名付けたファイルを作成し、BigQueryの一般公開データセットを参照するようにしています。
BigQueryにおいて、databaseがGoogle Cloudのプロジェクト名に対応し、schemaがデータセット名に対応し、tablesがテーブル名に対応しています。
version: 1
sources:
- name: samples_tables # データソースの名前
database: bigquery-public-data # プロジェクト名
schema: samples # データセット名
tables: # テーブル名一覧
- name: github_nested
- name: shakespeare
つまり、src_tables.ymlでは次の2つのテーブルを定義していることになります。
bigquery-public-data.samples.github_nestedbigquery-public-data.samples.shakespeare
これらのテーブルは、次のように データソースの名前 と テーブル名 を渡すことで呼び出すことが可能です。
FROM {{ source('samples_tables', 'github_nested') }}
また、この時点でのmodelsディレクトリ配下は次の通りです。
models
└── dbt_test
└── src_tables.yml
モデルを作成
次にビューを構成するモデルを作成します。
モデルとは、データの変換や集計を行うSQLクエリを指します。
以下のクエリをmart.sqlと名付けたファイルに登録しました。
中身は非常にシンプルでsourceで定義したそれぞれのテーブルからデータ件数を取得し、結合するクエリになります。
{{
config(
materialized='view'
)
}}
WITH github_nested_cnt AS (
SELECT
'github_nested' AS table_name,
COUNT(*) AS cnt
FROM
{{ source('samples_tables', 'github_nested') }}
),
shakespeare_cnt AS (
SELECT
'shakespeare' AS table_name,
COUNT(*) AS cnt
FROM
{{ source('samples_tables', 'shakespeare') }}
)
SELECT
table_name,
cnt
FROM
github_nested_cnt
UNION ALL
SELECT
table_name,
cnt
FROM
shakespeare_cnt
クエリの冒頭でMaterializationをviewに指定しています。
本ブログではMaterializationの詳細については触れませんが、viewに指定することで上記のクエリをビューとして登録することが可能です。
そして最終的には、次のようなディレクトリ構成になりました。
models
└── dbt_test
├── mart.sql
└── src_tables.yml
動かしてみる
では最後にdbt runで実際に動かしてみます。
$ dbt run
Running with dbt=1.8.3
Registered adapter: bigquery=1.8.2
Unable to do partial parsing because a project config has changed
Found 1 model, 2 sources, 471 macros
Concurrency: 1 threads (target='dev')
1 of 1 START sql view model dbt_dataset.mart ................................... [RUN]
1 of 1 OK created sql view model dbt_dataset.mart .............................. [CREATE VIEW (0 processed) in 1.76s]
Finished running 1 view model in 0 hours 0 minutes and 5.75 seconds (5.75s).
Completed successfully
Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
正常に成功し、以下のキャプチャのようにdbt_datasetのデータセット配下にmartというビューが作成されました。
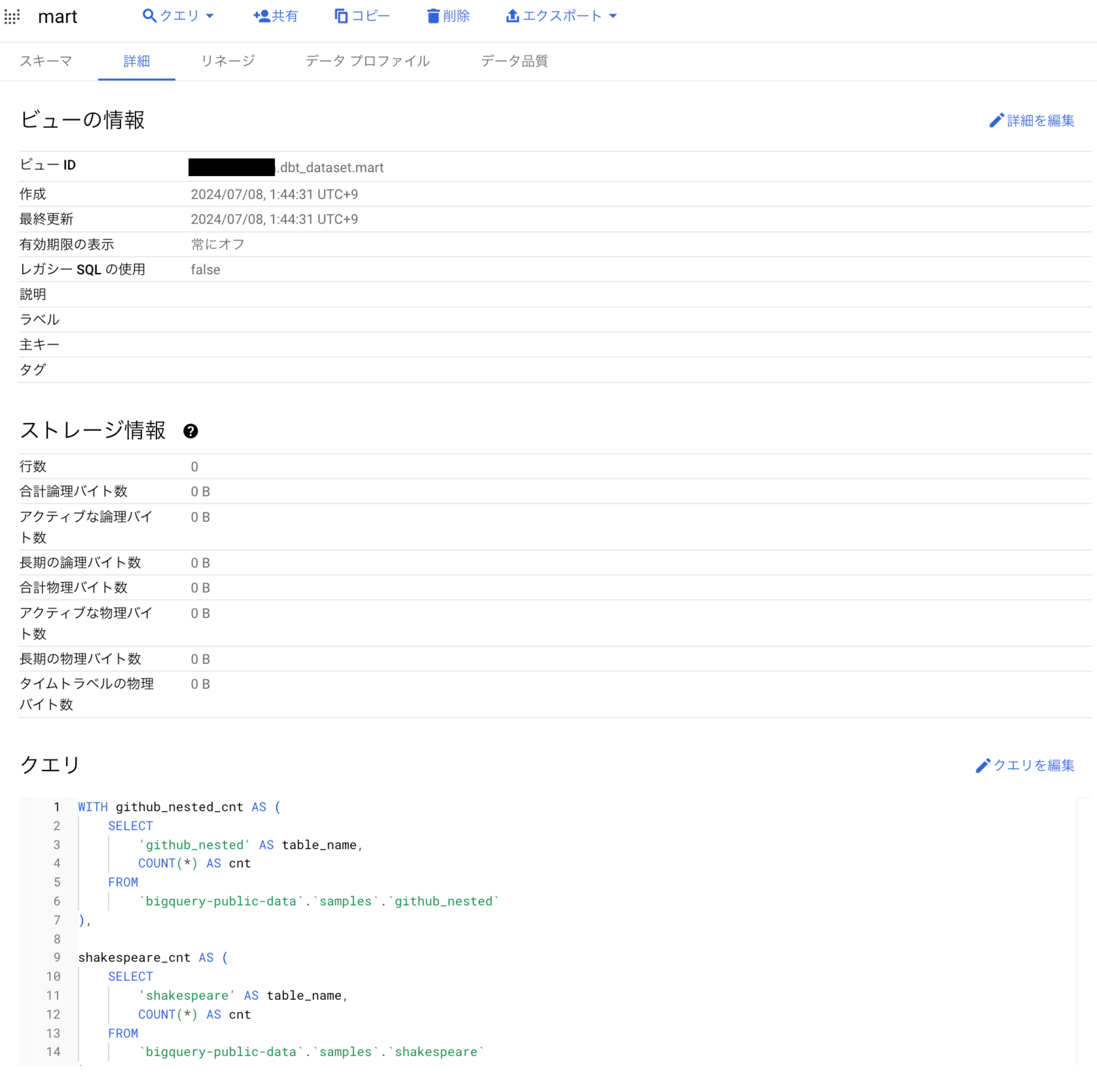
まとめ
今回のブログでは、自分でテーブルをsourceとして登録し、モデルでビューを作成してみました。
次回以降は、Materializationについて詳しく紹介したり、テストについて紹介したりしたいと思います。
それではまた!









